开题报告填写要求
1.开题报告(含“文献综述”)作为毕业设计(论文)答辩委员会对学生答辩资格审查的依据材料之一。此报告应在指导教师指导下,由学生在毕业设计(论文)工作前期内完成,经指导教师签署意见及所在专业审查后生效;
2.开题报告内容必须用黑墨水笔工整书写或按教务处统一设计的电子文档标准格式(可从教务处网页上下载)打印,禁止打印在其它纸上后剪贴,完成后应及时交给指导教师签署意见;
3.“文献综述”应按论文的格式成文,并直接书写(或打印)在本开题报告第一栏目内,学生写文献综述的参考文献应不少于15篇(不包括辞典、手册);
4.有关年月日等日期的填写,应当按照国标GB/T 7408—94《数据元和交换格式、信息交换、日期和时间表示法》规定的要求,一律用阿拉伯数字书写。如“2004年4月26日”或“2004-04-26”。
文献综述
结合毕业设计(论文)课题情况,根据所查阅的文献资料,每人撰写2000字左右的文献综述
研究背景及国内外研究现状
卷积神经网络(CNN)现在是许多学科研究的热点之一,被广泛用于多种领域,特别是在模式识别、图像处理、计算机视觉等方面。但是卷积神经网络的主要问题在于计算量太大,特别是其中的卷积层,以Alex-Net为例,占用了90%[@chenEyerissEnergyefficientReconfigurable2016]以上的计算量,卷积神经网络的硬件加速逐渐成为一个热门的研究问题。由于卷积神经网络自身特点,层与层之间可以看做顺序执行,而层内则有着较高的并行性,因此提高层内计算的并行度成为加速卷积神经网络的一个重要方向。
在2009,Farabet等人1提出来一种基于FPGA的CNN,该结构使用卷积单元来处理数据,并使用一个通用CPU来控制卷积单元。但是由于FPGA资源的限制,该平台只实现了一个卷积核。如果计算需要多个卷积核,那么只能串行执行。2013年,Peemen等人2实现了一个以存储为中心的CNN协处理器,它利用CNN大量内存访问的特点,在存储部分使用SRAM,而PE部分使用SIMD指令。2015年,清华大学的方睿等人,提出一种多级流水线的管道加速器方案。CPU通过PCIE通道提供数据并进行控制整个逻辑单元。近年来,中科院的陈天石等人提出来DianNao系列的加速器3,目前是卷积神经网络硬件加速领域的较优的一种方案,可以实现多种结构的卷积网络,如MLP、CNN、DNN。存硬件实现的卷积神经网络加速器通用性不好。尽管可以通过配置来实现更多的结构,但是它的灵活性远不如通用CPU。因此可重构加速器与通用CPU相结合的模式是一种高效地解决卷积神经网络加速问题的方案。
但是在这种定制结构中,CPU的选择具有极大的挑战。通常商业授权的IP会限制对指令集的修改,影响卷积神经网络加速器的实现效果。并且,商业授权的IP通常需要高昂的授权费,不利于高校和个人的研究。因此需要一个开源的指令集架构来进行定制加速器的研究。
RISC-V是一种新的开源指令集架构(ISA)4,目前已经有了一个完整的硬件和硬件生态56,包括完整的指令集、相应的编译器、模拟器和工具链。利用开源的RISC-V处理器,研究人员可以方便地将可重构加速器整合进SOC,并拓展相应的指令集来实现加速器的软件接口。
设计目标及平台的选择
本设计主要包含三个部分,RISC-V Core和卷积神经网络加速器,以及将两部分结合起来实现完整功能的SOC部分。卷积神经网络的硬件加速通常可以采用ASIC或者FPGA来实现,两者均是采用定制的硬件电路来加速算法。通常ASIC的性能跟高,功耗更低,但是由于成本过高,因此在本设计中采用FPGA作为硬件平台。
由于硬件实现CNN加速器需要较多资源,因此需要一款大容量的FPGA芯片,以实现更好的硬件加速效果。考虑各方面因素,最终选取了Nexys4 DDR作为硬件平台。Nexys4 DDR上使用Xilinx XC7A100T FPGA芯片。芯片包含了15,850个可编程逻辑单元,每个逻辑单元有4个6输入查找表和8个触发器。芯片有4,860 Kbits的块存储器,240个DSP运算单元,逻辑资源相对丰富。开发板引出数十个IO口和一个VGA接口,拥有128MB的DDR2,足够该系统使用。
研究意义及前景
卷积神经网络作为目前深度学习的一个重要手段,由于计算量巨大的问题限制了其应用于发展,通常需要在高性能的运算平台上进行模型的推演,因此主要被应用在主机场景,而非便携式应用。而利用卷积神经网络层内并行的特点,对卷积神经网络进行硬件加速,从而极大地提高了卷积网络的运行速度,使得便携设备也可以进行卷积神经网络运算,极大地拓展了深度学习的应用场合。
参考文献
研究手段
本课题要研究或解决的问题和拟采用的研究手段(途径)
本课题要研究的问题
本课题设计搭建一个RISC-V处理器的SOC,并设计卷积神经网络加速器作为协处理器与RISC-V处理器配合工作,实现在低成本的嵌入式平台上进行卷积神经网络加速运算。
本课题设计了一种RISC-V指令集的卷积神经网络处理器,实现了在低成本的嵌入式平台上进行卷积神经网络加速运算。本课题主要实现了以下功能:
使用RISC-V处理器搭建一个完整的SOC,包含RISC-V Core、片上总线、Debug调试模块以及基本的外设。
设计可重构的卷积神经网络加速器,并将其作为协处理器,并为其设计设计专用的指令,包括矢量存储指令,矢量加载指令,矢量加法指令和卷积运算指令以加快卷积过程的执行速度。
本课题拟采用的研究手段
本课题设计主要包含两部分,搭建RISC-V处理器核设计卷积神经网络加速器。整体结构如下图所示:
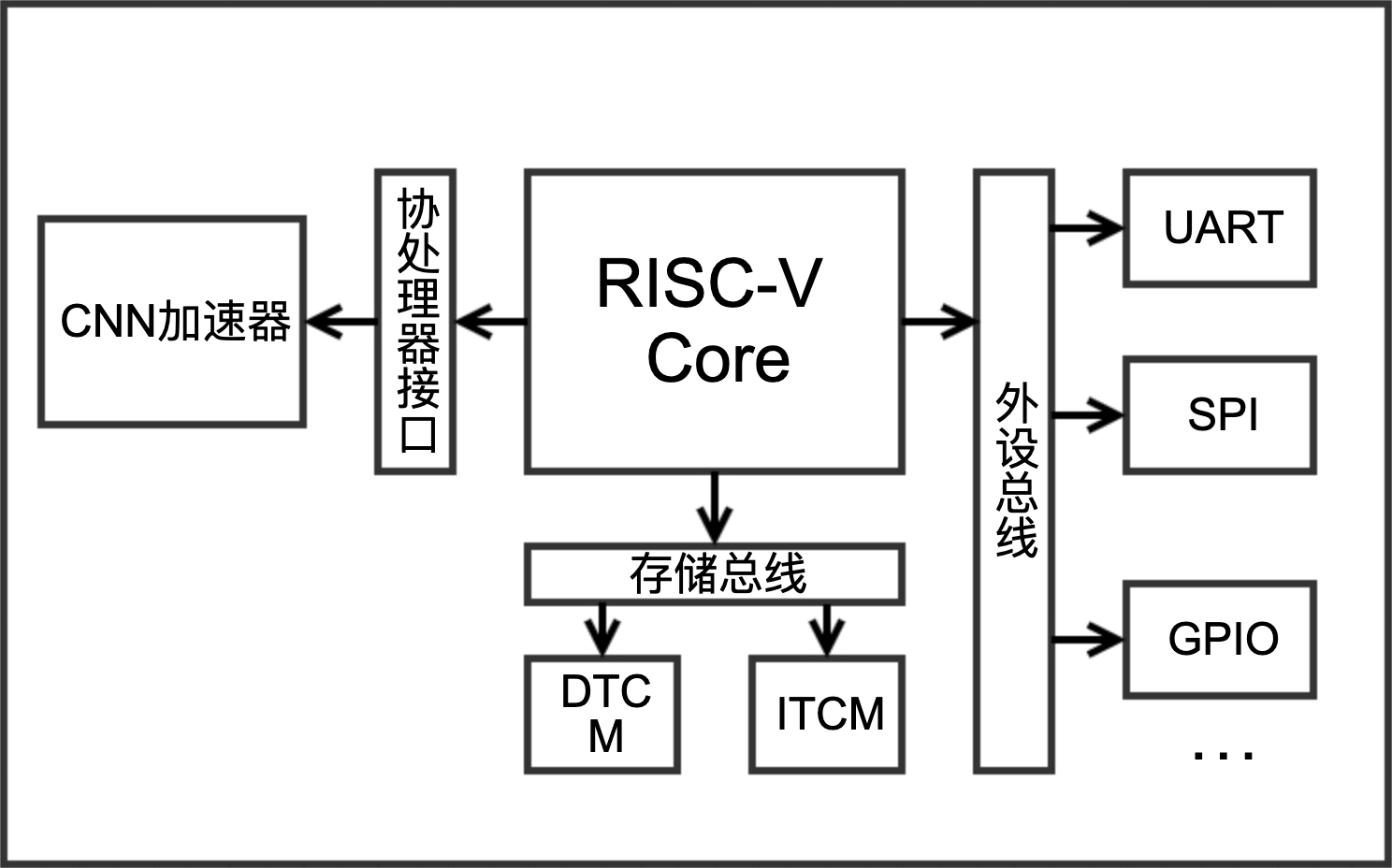
在RISC-V处理器的选取上有两种方案,一是使用已有的开源处理器,如Hummingbird E200、PicoRV32、Ibex等,二是自己设计整个处理器。考虑到第二种方案工作量过大,且性能难以达到较优的水平,一次在本课题采用了现有的开源RISC-V处理器。在对比各种各种处理器的特点之后,最终采取了Ibex RISC-V Core。Ibex是一个小型高效的32位有序RISC-V内核,具有2级流水线,可实现RV32IMC指令集。
在卷积神经网络加速器的设计部分,CNN算法在通用CPU上运行时,在卷积部分用循环实现,因此在宏观上,加速卷积神经网络有两种思路:1. 改变循环嵌套的先后顺序,提高数据的重用率,减少对外部存储的访问;2. 将一些低层循环进行Unroll操作展开,利用低层循环中数据相互不依赖的特性,有进行并行计算的可能7。本设计中,采取了第二种方案,将层内的循环进行展开,从而实现对卷积神经网络算法的硬件加速。
C. Farabet, C. Poulet, J. Y. Han, and Y. Lecun, “Cnp: An fpga-based processor for convolutional networks,” in International Conference on Field Programmable Logic & Applications, 2009.↩︎
M. Peemen, A. A. A. Setio, B. Mesman, and H. Corporaal, “Memory-centric accelerator design for convolutional neural networks,” 2013.↩︎
T. Chen, Z. Du, N. Sun, J. Wang, C. Wu, Y. Chen, and O. Temam, “Diannao: a small-footprint high-throughput accelerator for ubiquitous machine-learning,” Acm Sigplan Notices, vol. 49, no. 4, pp. 269–284, 2014.↩︎
The RISC-V instruction set manual↩︎
K. Asanovic and D. Patterson. Instruction Sets Should Be Free: The Case for RISC-V. Technical Report UCB/EECS-2014-146, EECS Department, University of California, Berkeley, Aug 2014.↩︎
RISC-V Foundation. http://www.riscv.org, 2017 (accessed Aug 15, 2017).↩︎
陆志坚 . 基 于 FPGA 的卷积神经网络并行结构研究 [ D ] 哈尔滨:哈尔滨工程大学,2013.↩︎