更正!!!
tensorflow1.14.0 似乎有 bug,在 NVIDIA 2070 super 上运行时会直接把显存占满,导致进程被 kill,换成 tensorflow1.15.3 后就好了,因此最终配置如下:
Software Version nvidia driver nvidia-440.82 Python 3.6.9 tensorflow tensorflow-gpu==1.15.3 cuDNN 7.6.4 CUDA 10.1(V10.1.243)
安装 NVIDIA 显卡驱动
下载 NVIDIA 显卡对应的驱动,下载后的文件格式为 .run
bios 禁用 secure boot,也就是设置为 disable
如果没有禁用 secure boot,会导致 NVIDIA 驱动安装失败,或者不正常。
禁用 nouveau 开源驱动
编辑 /etc/modprobe.d/blacklist.conf 文件,在最后加入:
1
blacklist nouveau
由于nouveau是在内核中的,还需要更新一下,执行如下命令:
1
sudo update-initramfs -u
之后重启电脑:
1
sudo reboot
重启后查看禁用是否成功:
1
lsmod | grep nouveau
没有输出代表nouveau被禁用了
关闭 GUI 界面,进入命令行模式
1
sudo telinit 3
安装 NVIDIA 驱动
如果以前安装过 nvidia 驱动,需要卸载:
1
sudo apt-get autoremove –purge "*nvidia*"
首先给驱动文件增加可执行权限:
1
sudo chmod a+x NVIDIA-Linux-*******.run
然后执行安装:
1
sudo sh ./NVIDIA-Linux-*******.run -no-opengl-files
安装完成后重启 !!!
–no-opengl-files 参数必须加否则会循环登录,也就是 loop login
参数介绍:
–no-opengl-files 只安装驱动文件,不安装 OpenGL 文件,这个参数最重要; –no-x-check 安装驱动时不检查 X服务; –no-nouveau-check 安装驱动时不检查 nouveau; 后面两个参数可不加。
最后切换回 GUI 界面
1
sudo telinit 5
输入 nvidia-smi 查看驱动安装是否成功
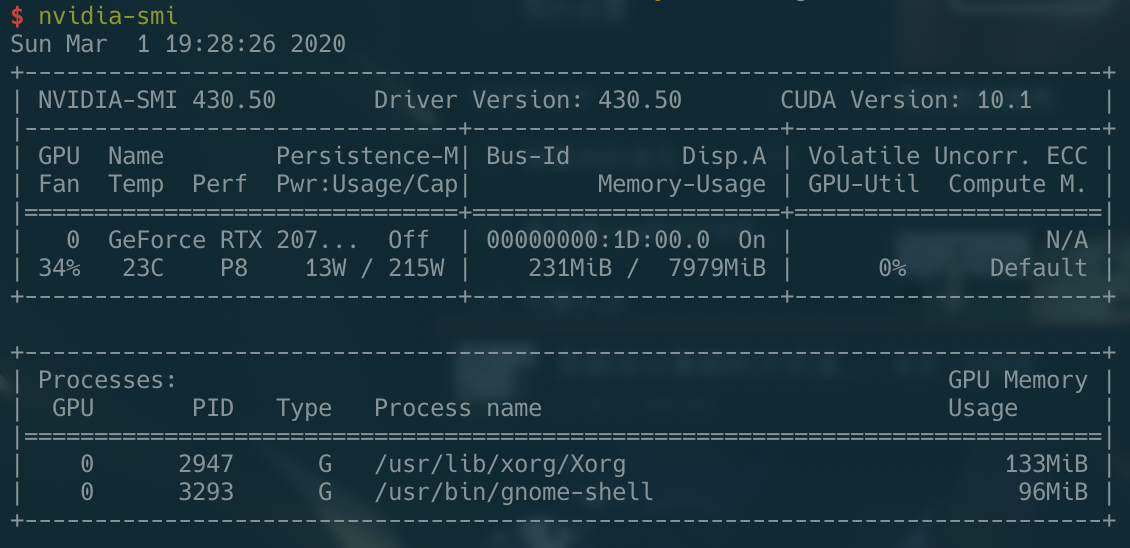
最后我装的是 430.50 版本的驱动
显示使用核显,计算使用独显
https://forums.developer.nvidia.com/t/ubuntu-18-04-headless-390-intel-igpu-after-prime-select-intel-lost-contact-to-geforce-1050ti/66698
1 | sudo prime-select nvidia |
add ‘nogpumanager’ kernel parameter
create /etc/X11/xorg.conf
1 | Section "Device" |
安装 CUDA (version 10.0)
Tensorflow 与 CUDA 有对应关系,可以参考这里,主要是因为
tensorflow 会调用 usr/local/cuda/lib64 目录下的
.so 文件,我尝试过了,1.14,1.15
版本的 tensorflow 调用的都是 10.0 的 cuda,装错版本会提示
.so 文件找不到
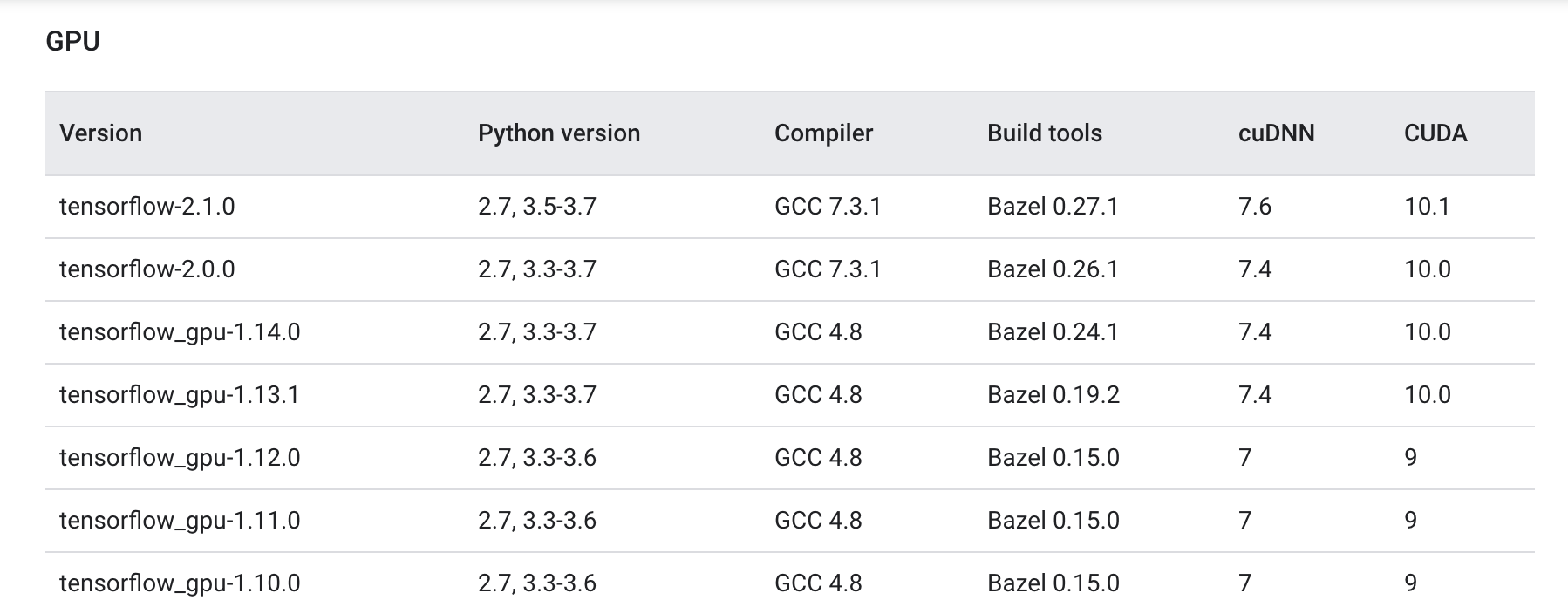
我要装的是 Tensorflow-gpu 1.14.0,因此我安装 CUDA10.0 和 cuDNN7.4
下载 CUDA https://developer.nvidia.com/cuda-toolkit-archive

运行如下命令安装
1 | sudo sh cuda_<version>_linux.run |
安装过程中会有一些选项,显卡驱动不要装 !!! 因为之前已经装过了
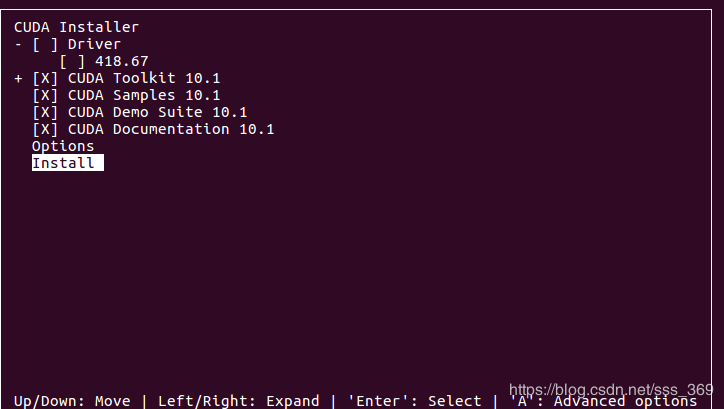
安装完成输出的 log 会有提示
最后将cuda添加到系统环境中
1 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 |
检查是否安装成功:
1 | nvcc -V |
安装 cudnn (version 7.4.2)
下载 cuDNN v7.4.2 (Dec 14, 2018), for CUDA 10.0

解压后,会得到一个名为 cuda 的文件夹,将问价拷贝到 cuda 的安装目录下
注意!!! cuda/lib64
里的文件有链接的结构,如下,不能直接 cp,使用 -a
参数可以保持软链接结构

1 | sudo cp -a cuda/lib64/libcudnn* /usr/local/cuda-10.0/lib64/ |
需要注意下这几个文件的权限!!!
测试 CUDA 是否安装成功
切换到测试目录下:
1
cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
编译
1
sudo make
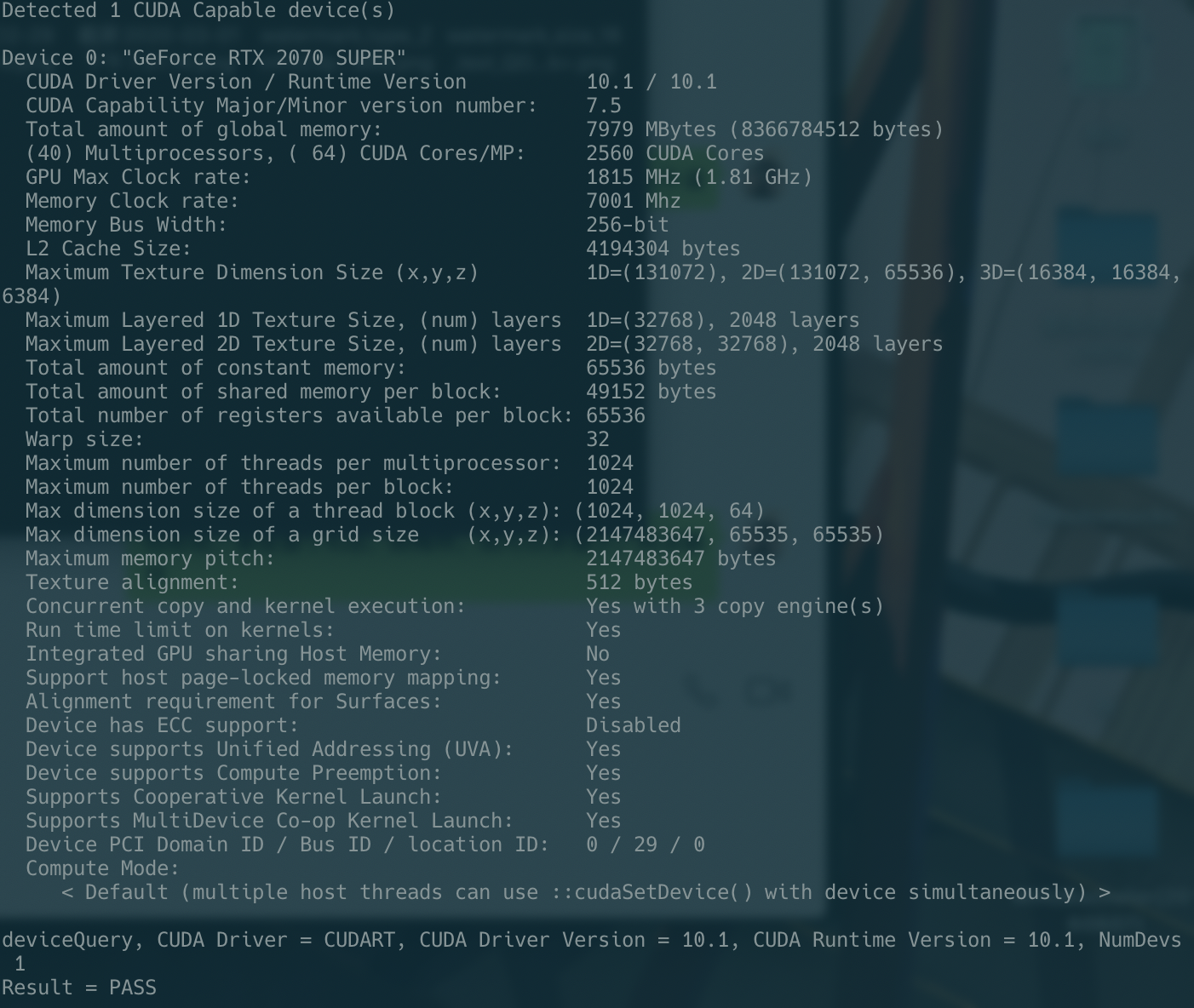
进行测试,运行文件
1
./deviceQuery
会看到类似这种结果:
安装多个版本的 cuda
因为 cuda 安装目录下是用软链接的方式实现的,因此我们可以安装多个版本的 cuda,只要将软链接链接到对应的 cuda 就行,如下:

使用命令:
1 | rm -rf cuda # 删除原来的软链接 |
注意环境变量的修改,可以将 cuda-
1 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 |
最后查看当前的 cuda 版本
1 | nvcc -V |
如果确实软链接修改成功了,环境变量也改好了,版本依旧没有切换,尝试重启一下
安装 tensorflow
坑!!!
Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR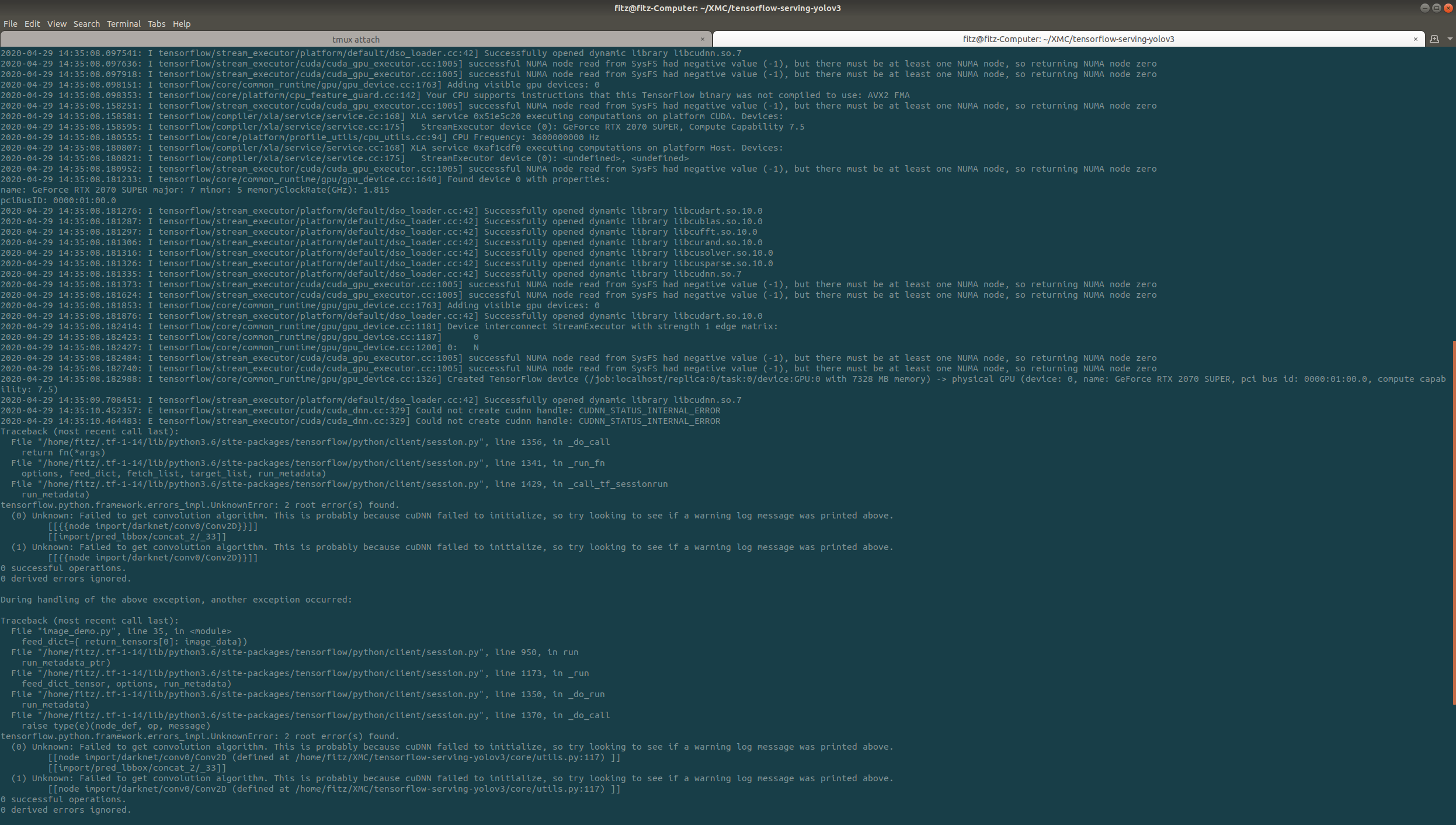
这个报错可能是 tensorflow 和 cuda 版本不符合,但如果已经按照推荐列表里的对应关系安装了 tensorflow 和 cuda,任然这样报错就可能是 tensorflow 占用的显存过多,进程直接被系统 kill 了,因此可以对 tensorflow 的显存进行限制。
参考:http://www.cnblogs.com/darkknightzh/p/6591923.html
定量设置显存
1
2gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))在程序开始的地方加上这两行,这样运行TensorFlow程序时,每个使用的GPU中,占用的显存都不超过总显存的0.7。
按需设置显存
1
2gpu_options = tf.GPUOptions(allow_growth=True)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))这样设置以后,程序就会按需占用GPU显存。